L’automatisation des tests est une pratique aujourd’hui très ancrée dans bon nombre d’organisations conscientes que les tests de régression manuels ne sont plus suffisants pour répondre aux enjeux de qualité, lorsque le time-to-market est un point clé d’un secteur d’activité donné.
Autour de l’automatisation des tests, on peut inclure plusieurs niveaux de tests. Automatiser des tests peut ainsi signifier :
Au niveau des développements,
couvrir un maximum de lignes de code avec des tests unitaires, par nature automatisés, avec des frameworks dépendants des langages utilisés comme JUnit pour Java, PHPUnit pour PHP, NUnit pour .Net, Mocha ou Jasmine pour JavaScript…
Au niveau du Middle-Office,
des tests d’API Rest, de Webservices SOAP, ou encore de flux, quels qu’ils soient, avec des End Points à couvrir avec des tests d’intégration.
Au niveau des écrans,
avoir des tests qui se mettent à la place des utilisateurs finaux. Ils cliquent seuls sur des boutons, sélectionnent des valeurs dans des listboxes, écrivent du texte dans des champs, font des double-clics, des drag & drop, etc mais aussi vérifient les résultats obtenus lors de chaque exécution, en les comparant automatiquement avec des résultats attendus : bref, ces tests automatisés doivent eux-mêmes comporter les assertions qui en font toute leur valeur.
C’est à ce dernier niveau que cet article s’intéresse en premier lieu, c’est-à-dire aux tests qui interagissent automatiquement avec les éléments aussi divers que variés que l’on peut trouver sur un écran.
Cet écran peut être d’une nature extrêmement spécifique : une page Web destinée au grand public (BtoC), à un public restreint (BtoB), un écran sous un ERP, un écran sous un outil de CRM, une application client lourd présente sur un poste de travail, un écran sous CICS… La suite de cet article concerne des écrans Web, avec les mêmes problématiques quelle que soit la technologie que l’on pourrait rencontrer.
Lorsqu’on a à automatiser des tests sur des écrans, il est important de prendre en compte le plus tôt possible la maintenabilité des scripts de tests automatisés, afin que ces derniers puissent apporter une réelle valeur ajoutée dans la durée.
En effet, en mettant la main opérationnellement dans des projets d’automatisation des tests, qui n’a pas déjà pesté sur un test automatisé qui est en échec, alors même que le geste métier fonctionne, lui, manuellement ? Nous faisons référence ici à un test qui a toujours fonctionné, et qui soudainement ne fonctionne plus, avec la nouvelle version de l’application qui vient d’être livrée sur notre environnement de test.
Une explication de cet échec, et de la maintenance qui en découle, est bien souvent le fait que la manière dont notre script de test automatisé reconnaît un élément n’est plus d’actualité : le bouton qui était parfaitement reconnu et actionné jusque là a soudainement évolué. Il va falloir revenir sur le test pour qu’il puisse de nouveau cliquer sur le bouton en question…
Outre le fait que l’automaticien de l’équipe n’était pas au courant de cette modification (et cela est un autre sujet), il va falloir maintenant maintenir le test pour qu’il puisse de nouveau interagir avec ce bouton qui vient de changer. Cette situation est bien connue des automaticiens, et il y a fort à parier que tout ici est une question de Selector et/ou de Locator, qu’il va falloir faire évoluer.
Selectors et Locators : qu’est-ce-que c’est ?
Tout élément présent sur une page Web (un bouton, un champ, une listbox, une image…) dispose de propriétés, parfois nombreuses, qui ont été codées par les développeurs ayant une orientation Front dans une équipe. Ces propriétés sont accessibles via le DOM (Document Object Model), représentation des données des objets comprenant la structure et le contenu de l’ensemble des éléments d’une page Web. La bonne nouvelle, c’est qu’il suffit de faire « F12 » sur votre navigateur, pour accéder à ce DOM (ou alors un clic droit, puis « Inspecter ») !
Exemple : sur le site web www.google.com, voici ce qu’on obtient lorsqu’on fait « F12 ».
Le DOM
Depuis la console, il est possible de voir les propriétés d’un élément particulier sur cette page Web. Prenons l’exemple du champ de recherche : on peut voir ses propriétés via le bouton de sélection des éléments de la page. Après avoir cliqué sur ce bouton, il suffit de cliquer sur le champ de recherche : on voit alors les propriétés de cet élément précis.
Dans le DOM, on voit ainsi les éléments ci-contre (bien entendu, cela peut évoluer au fil des releases du site web www.google.com)

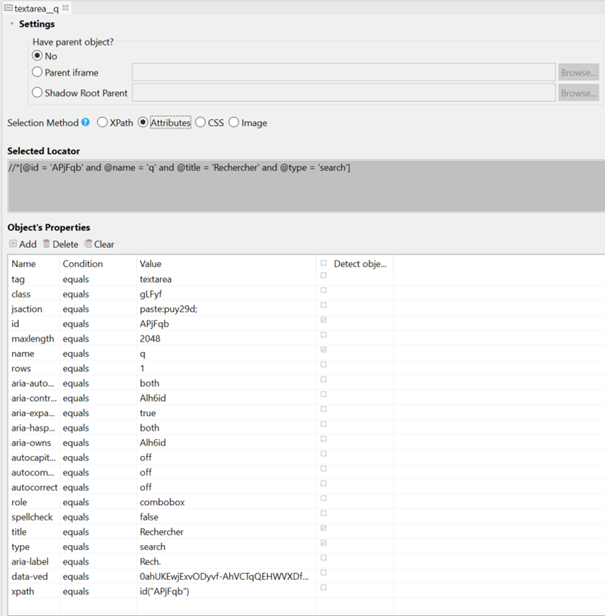
On peut voir ici qu’il existe plusieurs propriétés sur le champ de recherche. Techniquement, il s’agit d’un textarea, avec les propriétés (ou Selectors) suivantes :
- Selector class, qui a la valeur « gLFyf »
- Selector jsaction, qui a la valeur « paste:puy29d; »
- Selector id, qui a la valeur « APjFqb »
- Selector name, qui a la valeur « q »
- Selector title, qui a la valeur « Rechercher »
- …
D’emblée, il est important d’identifier dans cette liste de Selectors celui (ou ceux) qui sont les moins susceptibles d’évoluer dans le temps ou encore ceux qui peuvent changer à chaque fois qu’on recharge la page Web.
Dans cet exemple, on pourrait retenir le Selector « name » (avec la valeur « q »), ainsi que le Selector « title » (avec la valeur « Rechercher »).
Ces deux Selectors peuvent nous permettre de créer le Locator (localisateur) qui sera le plus robuste et le plus pérenne dans le temps.
De la bonne utilisation du DOM
Pour construire ce Locator, il existe une astuce qui est assez simple. Depuis le DOM, faire un « Ctrl + F » pour faire apparaître un champ permettant de rechercher un élément via son Locator.
L’idée est d’écrire le Locator dans ce champ en se servant des Selectors intéressants identifiés, et en s’assurant de l’unicité de l’élément qui va correspondre à ce Locator.
Ici, on a écrit « //textarea[@name= »q »] » et on peut voir à droite les chiffres « 1 of 1 » : cela signifie bien qu’on a un seul élément sur la page qui correspond à ce Locator : on peut donc utiliser ce Locator en toute confiance dans notre script de test automatisé.
Il est à noter que d’autres Selectors existent également sur ce champ de recherche : CSS, XPath… On peut les copier en faisant un clic droit dans le DOM, et les utiliser également dans la constitution du Locator.
Pour aller plus loin
Les outils d’automatisation des tests Front ont-ils des fonctionnalités permettant de gérer automatiquement les Selectors et les Locators ?
Oui, bien entendu : et comme tout ce qui est automatique, il convient d’avoir un œil critique sur les Selectors qu’un outil aura sélectionnés. D’autant que chaque outil a un fonctionnement qui peut être assez différent sur ce sujet.
Les atouts de Katalon Studio
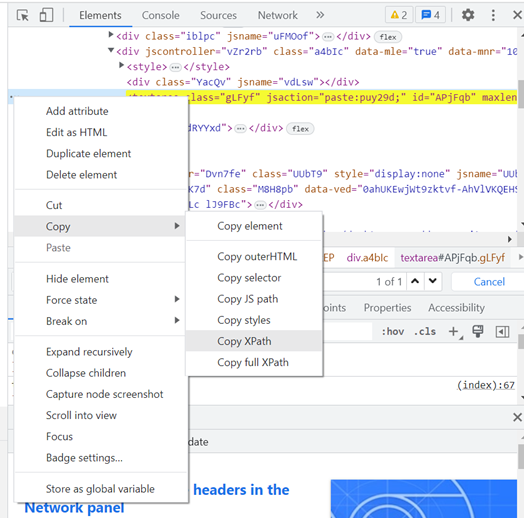
Katalon Studio prend par défaut une multitude de Selectors, et il est souvent primordial de repasser sur les éléments capturés pour s’assurer de la pertinence des Selectors pris en compte pour la reconnaissance des éléments.
Dans cet exemple, il sera pertinent de désélectionner certains Selectors, afin de limiter leur nombre, et les impacts sur la maintenance des tests automatisés.
Il est à noter que Katalon Studio permet de prioriser l’ordre de priorité des Selectors à prendre en compte.
Exemple avec Playwright
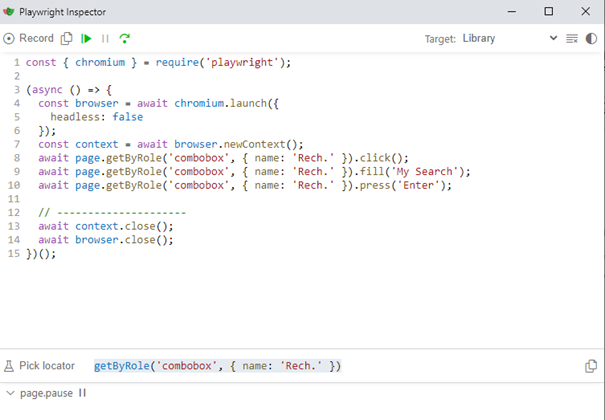
En utilisant Playwright Inspector, la fonctionnalité de Capture propre à Playwright, on obtient le code suivant après avoir actionné le champ de recherche du site www.google.com.
Le Locator généré est : getByRole(‘combobox’, { name: ‘Rech.’ })
Ce Locator peut être remplacé par //textarea[@name= »q »], ce qui garantira une meilleure robustesse dans le temps.
Quel que soit l’outil d’automatisation des tests Front que l’on utilise, il est primordial d’avoir une bonne connaissance de gestion des Selectors, afin de construire un Locator pertinent.
C’est un point primordial qui permettra de faciliter :
- La maintenance des scripts de tests automatisés (et également en utilisant le Page Object Model comme pattern de développement),
- La gestion des Flaky Tests, sujet de plus en plus présent dans les organisations, qui ont à gérer parfois des centaines de tests automatisés au quotidien, dont des dizaines qui sont en échec pour de mauvaises raisons,
- La relation entre l’automaticien et les développeurs Front de l’équipe qui pourraient avoir à créer de nouveaux Selectors pour faciliter le travail de l’automaticien.
A lire également

{kind=link}

Centraliser des résultats de tests automatisés dans Zephyr
Dans de nombreuses équipes, les tests manuels sont déjà centralisés dans un outil de gestion comme Zephyr, tandis que les tests automatisés s’exécutent ailleurs, souvent via des pipelines CI/CD.